Qdrant Query Image
Image Retrieval System with Qdrant & CLIP
A Streamlit application for semantic image search using vector embeddings and cosine similarity.
Pre-Requisites
Required Python packages:
- streamlit:
pip install streamlit - qdrant-client:
pip install qdrant-client - transformers:
pip install transformers - Pillow:
pip install Pillow - numpy:
pip install numpy
Additional requirements:
- Qdrant server running locally (
docker run -p 6333:6333 qdrant/qdrant) - CLIP model weights (automatically downloaded on first run)
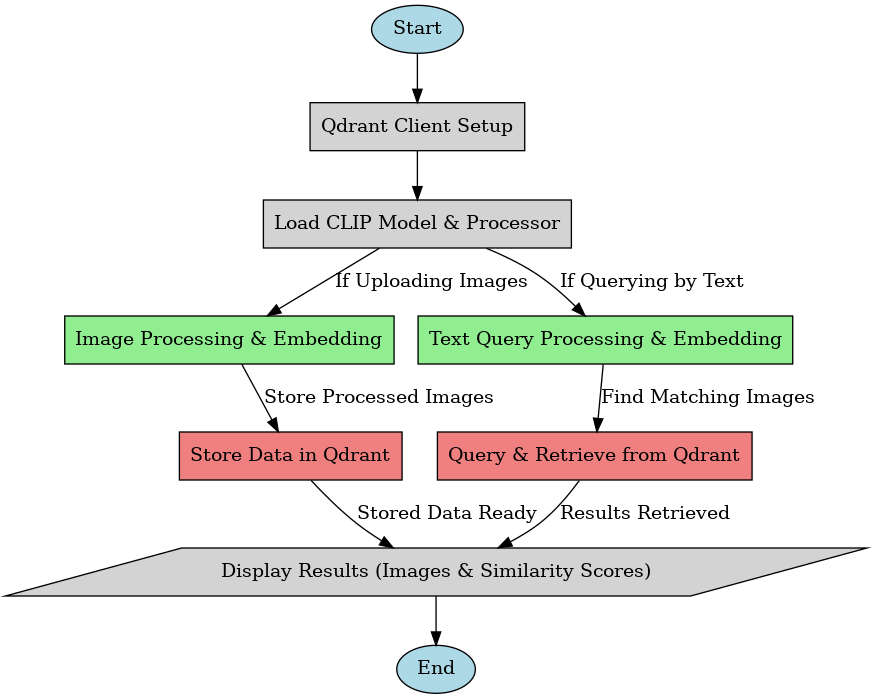
System Architecture
The application follows a multi-stage processing pipeline:
- Image Ingestion: Upload and preprocess images
- Embedding Generation: CLIP model creates 512-dimension vectors
- Vector Storage: Qdrant database stores embeddings with compressed images
- Query Processing: Text-to-embedding conversion and cosine similarity search
- Results Display: Top-k matches with similarity scores
Key Components Explained
1. Qdrant Client Initialization
qdrant_client = QdrantClient(host="localhost", port=6333)Establishes connection to local Qdrant vector database server.
2. CLIP Model Loading with Cache
@st.cache_resource
def load_clip_model():
clip_model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
clip_processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
return clip_model, clip_processorUses Streamlit's cache to load CLIP model/processor once per session.
3. Image Processing Pipeline
def process_uploaded_images(image_files, max_size=(800, 800), quality=80):
# Resize, convert to RGB, and compress images
# Returns processed images and byte streamsStandardizes image inputs while maintaining EXIF data and reducing storage needs.
4. Vector Storage Mechanism
points = []
for i, (embedding, file, img_bytes) in enumerate(...):
encoded_data = base64.b64encode(img_bytes).decode('utf-8')
payload = {"filename": file.name, "data": encoded_data}
points.append(PointStruct(id=i, vector=embedding, payload=payload))Stores base64-encoded images with their vectors for efficient retrieval.
User Interface Components
1. Image Storage Interface
image_files = st.file_uploader("Select images to store", ...)
collection_name_store = st.text_input("Enter Vectorstore Name...")
if st.button("Store Images"):
# Processing and storage logicMulti-file uploader with collection name management.
2. Semantic Search Interface
query_text = st.text_input("Enter Query Text...")
top_k = st.number_input("Enter number of images...")
if st.button("Find Similar Images"):
# Search and display logicNatural language query input with results ranking and visualization.
3. Result Visualization
data_url = f"data:image/jpeg;base64,{img_data}"
st.image(data_url, caption=f"{filename} (Score: {score:.4f})")Displays images with similarity scores using base64 embedding.
Complete Implementation: Qdrant_Query_Image.py
import streamlit as st
from qdrant_client import QdrantClient
from qdrant_client.http.models import PointStruct, VectorParams
from transformers import CLIPProcessor, CLIPModel
from PIL import Image
import numpy as np
import glob, os, re, base64
from io import BytesIO
# -------------------------------
# Qdrant Client Initialization
# -------------------------------
qdrant_client = QdrantClient(host="localhost", port=6333)
# -------------------------------
# Function to get image paths from a directory (if needed)
# -------------------------------
def get_image_paths(directory, extensions=("jpg", "jpeg", "png")):
image_paths = []
for ext in extensions:
image_paths.extend(glob.glob(os.path.join(directory, f"*.{ext}")))
return image_paths
# -------------------------------
# Load CLIP Model and Processor using st.cache_resource
# -------------------------------
@st.cache_resource
def load_clip_model():
clip_model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
clip_processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
return clip_model, clip_processor
# -------------------------------
# Function to generate embeddings from uploaded image files using CLIP
# -------------------------------
def generate_embeddings_from_files(image_files, clip_processor, clip_model):
images = [Image.open(file).convert("RGB") for file in image_files]
inputs = clip_processor(images=images, return_tensors="pt", padding=True)
embeddings = clip_model.get_image_features(**inputs)
return embeddings.detach().numpy()
# -------------------------------
# Function to write images to Qdrant from uploaded files
# -------------------------------
def write_images_to_qdrant_from_files(image_files, collection_name, clip_processor, clip_model):
# Process uploaded images: resize and compress them
def process_uploaded_images(image_files, max_size=(800, 800), quality=80):
images = []
image_bytes_list = []
for file in image_files:
try:
image = Image.open(file).convert("RGB")
image.thumbnail(max_size, Image.Resampling.LANCZOS)
buffered = BytesIO()
image.save(buffered, format="JPEG", quality=quality)
img_bytes = buffered.getvalue()
image_bytes_list.append(img_bytes)
images.append(image)
except Exception as e:
st.error(f"Error processing image {file.name}: {e}")
return images, image_bytes_list
images, image_bytes_list = process_uploaded_images(image_files)
embeddings = generate_embeddings_from_files(image_files, clip_processor, clip_model)
# Delete collection if it exists
if qdrant_client.collection_exists(collection_name):
qdrant_client.delete_collection(collection_name)
# Create new collection with proper vector configuration
qdrant_client.create_collection(
collection_name=collection_name,
vectors_config=VectorParams(size=embeddings.shape[1], distance="Cosine")
)
# Store full image data as base64 along with filename in payload
points = []
for i, (embedding, file, img_bytes) in enumerate(zip(embeddings, image_files, image_bytes_list)):
encoded_data = base64.b64encode(img_bytes).decode('utf-8')
payload = {"filename": file.name, "data": encoded_data}
points.append(PointStruct(id=i, vector=embedding.tolist(), payload=payload))
qdrant_client.upsert(collection_name=collection_name, points=points)
st.success(f"{len(image_files)} images have been stored in Qdrant collection '{collection_name}'.")
# -------------------------------
# Function to generate text embedding using CLIP (for query text)
# -------------------------------
def generate_text_embedding(query, clip_processor, clip_model):
inputs = clip_processor(text=[query], return_tensors="pt", padding=True)
embeddings = clip_model.get_text_features(**inputs)
return embeddings.detach().numpy()[0]
# -------------------------------
# Function to read similar images from Qdrant based on a query text
# -------------------------------
def read_similar_images_from_qdrant_text(query_text, collection_name, clip_processor, clip_model, top_k=5):
query_embedding = generate_text_embedding(query_text, clip_processor, clip_model)
results = qdrant_client.search(
collection_name=collection_name,
query_vector=query_embedding.tolist(),
limit=top_k
)
# Enrich each payload with the score (cosine similarity)
similar_payloads = []
for result in results:
payload = result.payload
# Attach the similarity score from the result (if available)
payload["score"] = result.score if hasattr(result, "score") else None
similar_payloads.append(payload)
return similar_payloads
# -------------------------------
# Streamlit Interface
# -------------------------------
st.title("Image Retrieval with Qdrant and CLIP")
st.write("Store images in a Qdrant vector database and fetch best matching images based on a query text.")
# Section 1: Store Images in Qdrant
st.header("Store Images in Qdrant")
image_files = st.file_uploader("Select images to store", type=["jpg", "jpeg", "png"], accept_multiple_files=True)
collection_name_store = st.text_input("Enter Vectorstore (Qdrant Collection) Name for Storage:", value="my_image_collection")
if st.button("Store Images"):
if not image_files:
st.error("Please select at least one image.")
else:
clip_model, clip_processor = load_clip_model()
try:
write_images_to_qdrant_from_files(image_files, collection_name_store, clip_processor, clip_model)
except Exception as e:
st.error(f"An error occurred while storing images: {e}")
# Section 2: Query Similar Images by Text
st.header("Query Similar Images")
collection_name_query = st.text_input("Enter Vectorstore (Qdrant Collection) Name to Query:", value="my_image_collection")
query_text = st.text_input("Enter Query Text to search image:", value="A cat sitting on the chair")
top_k = st.number_input("Enter number of images to retrieve (k):", value=5, min_value=1, step=1)
if st.button("Find Similar Images"):
if not collection_name_query.strip():
st.error("Please enter a valid Qdrant Collection Name for query.")
elif not query_text.strip():
st.error("Please enter a query text.")
else:
clip_model, clip_processor = load_clip_model()
try:
similar_payloads = read_similar_images_from_qdrant_text(query_text, collection_name_query, clip_processor, clip_model, top_k)
if similar_payloads:
st.write("### Similar Images Found:")
for payload in similar_payloads:
filename = payload.get("filename", "No filename")
img_data = payload.get("data")
score = payload.get("score")
if img_data:
data_url = f"data:image/jpeg;base64,{img_data}"
caption = f"{filename} (Cosine Similarity: {score:.4f})" if score is not None else filename
st.image(data_url, caption=caption, use_container_width=True)
else:
st.write(f"Image data not found for {filename}.")
else:
st.write("No similar images found.")
except Exception as e:
st.error(f"An error occurred while searching images: {e}")
if __name__ == "__main__":
st.write("Program executed.")
Running the Application
streamlit run Qdrant_Query_Image.pyAccess the interface at:
- Local URL: http://localhost:8501
- Network URL: http://[your-ip]:8501
Ensure Qdrant server is running before starting the application.
Conclusion
This system demonstrates a modern approach to content-based image retrieval using:
- Multimodal CLIP embeddings for cross-modal search
- Qdrant's efficient vector similarity search capabilities
- Streamlit's rapid interface development
The architecture supports extension to billion-scale datasets with horizontal scaling in Qdrant Cloud.
Sequence Flow of Image Retrieval System with Qdrant.
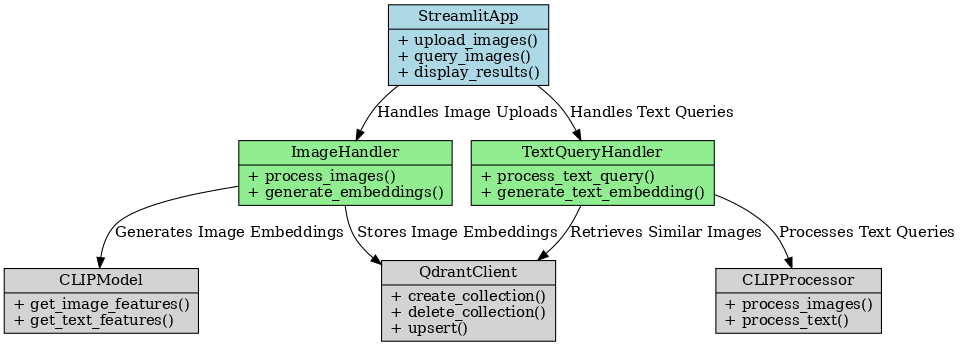
Class Diagram of Image Retrieval System with Qdrant.
User Query: Show all images
Here all the images will be displayed in ascending order, based on cosine similarity score.
User Query: A cat sitting on the chair
User Query: Cats sitting on the chair
User Query: People walking on the beach
User Query: Show images of stairs
Qdrant dashboard
Reference Links
- Qdrant Vector Database Installation: Qdrant Vector Database
- OpenAI CLIP: OpenAI CLIP
- openai/clip-vit-base-patch32: huggingface
- Streamlit: Streamlit Official Site
- Ollama Installation on Local Host: Ollama
- Running deepseek-r1:8b on Local Host using Ollama: Ollama Documentation