RAG PDF Parsing with Tavily Web Search Fallback
RAG PDF Parsing with Tavily Web Search Fallback
A Streamlit application for vector search and Tavily web search capabilities using Locally hosted LLM (deepseek-r1)
Pre-Requisites
Required Python packages:
- streamlit:
pip install streamlit - qdrant-client:
pip install qdrant-client - langchain:
pip install langchain - PyPDF:
pip install pypdf - sentence-transformers:
pip install sentence-transformers - Tavily: pip install
tavily-python
Additional requirements:
- Qdrant server running locally (
docker run -p 6333:6333 qdrant/qdrant) - Ollama server running with deepseek-r1:8b model
- Tavily API key for web search fallback
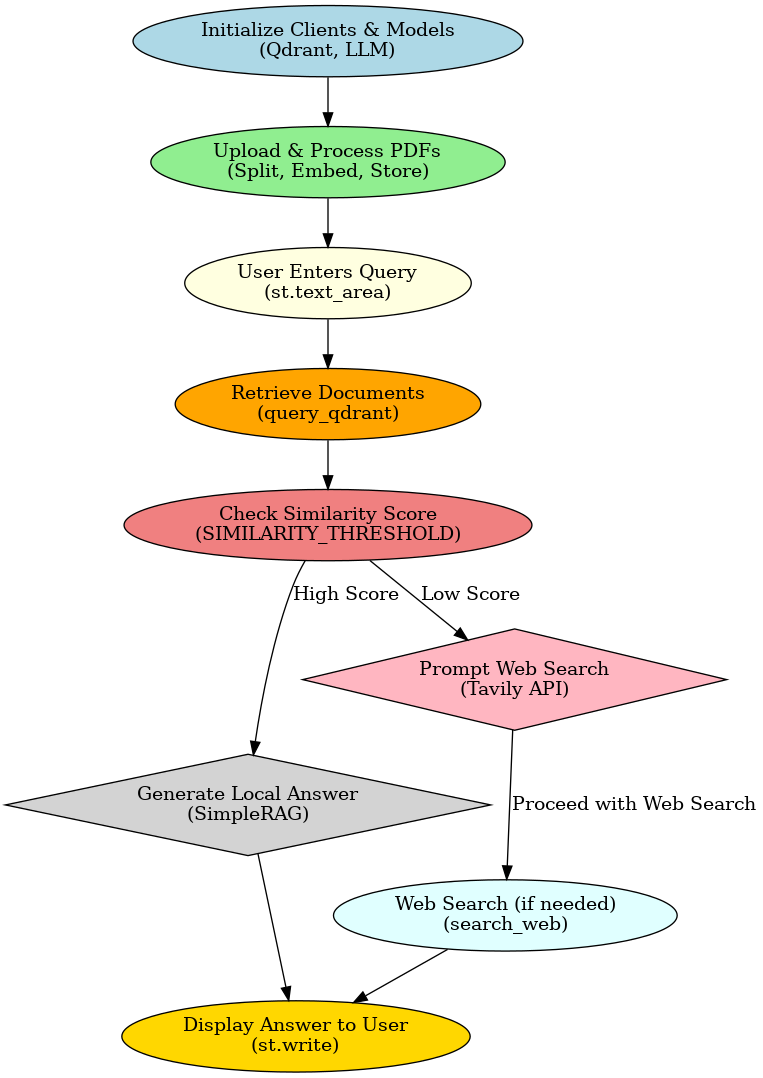
System Architecture
The application implements a hybrid retrieval pipeline:
- PDF Processing: Text extraction and chunking
- Embedding Generation: MiniLM-L6 model creates 384-dimension vectors
- Vector Storage: Qdrant database stores document chunks
- Query Processing: Local LLM (DeepSeek) with RAG pattern
- Fallback Mechanism: Tavily web search integration
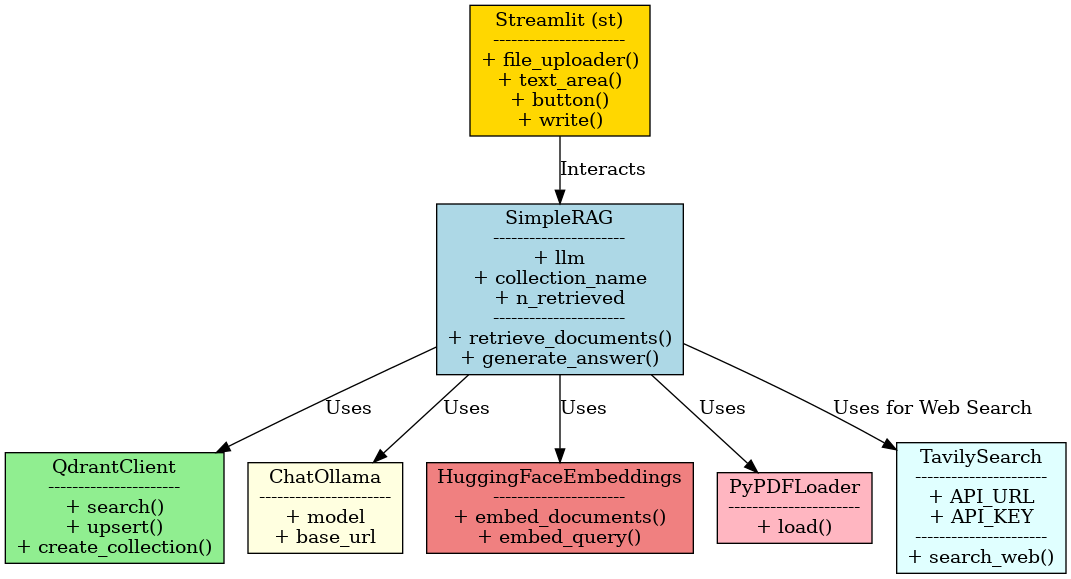
Key Components Explained
1. Document Processing Pipeline
def encode_pdfs_to_qdrant(uploaded_files, collection_name):
text_splitter = RecursiveCharacterTextSplitter(...)
embeddings = HuggingFaceEmbeddings(...)
# Chunking and vector storage logicHandles PDF text extraction, chunking, and vector embedding generation.
2. Hybrid Retrieval Class
class SimpleRAG:
def retrieve_documents(...):
# Qdrant vector search
def generate_answer(...):
# LLM response generation with fallbackCombines local vector search with web search fallback mechanism.
3. Local LLM Integration
llm = ChatOllama(
model="deepseek-r1:8b",
base_url="http://127.0.0.1:11434"
)Utilizes locally hosted Ollama LLM for answer generation.
User Interface Components
1. Document Storage Interface
uploaded_files = st.file_uploader("Upload PDFs", ...)
collection_name = st.text_input("Collection Name", ...)
if st.button("Upload to VectorDB"):
# Processing and storage logicMulti-PDF uploader with collection management.
2. Semantic Search Interface
query = st.text_area("Enter your question", ...)
if st.button("Search"):
# RAG processing and displayNatural language query input with confidence-based results.
3. Web Search Fallback
if result['status'] == 'needs_web_search':
st.warning(result['answer'])
if st.button("Proceed to Web Search"):
# Tavily API integrationAutomatic fallback to web search when local confidence is low.
Complete Implementation: RAG_PDF_Parsing_with_Tavily_web_search.py
"""
Copyright (c) 2025 AI Leader X (aileaderx.com). All Rights Reserved.
This software is the property of AI Leader X. Unauthorized copying, distribution,
or modification of this software, via any medium, is strictly prohibited without
prior written permission. For inquiries, visit https://aileaderx.com
"""
import streamlit as st
import os
import re
import requests
from qdrant_client import QdrantClient
from qdrant_client.http.models import PointStruct, VectorParams
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_community.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.schema import Document
from langchain.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough, RunnableSequence
from langchain.schema import StrOutputParser
from langchain_ollama.chat_models import ChatOllama
from sentence_transformers import SentenceTransformer, util
# Initialize Qdrant Client
qdrant_client = QdrantClient(host="localhost", port=6333)
# Llama3.2 / DeepSeek Model Configuration
llm = ChatOllama(
model="deepseek-r1:8b",
base_url="http://127.0.0.1:11434"
)
# Config Parameters
SIMILARITY_THRESHOLD = 0.2 # Default value to be updated by user input
# Helper Functions
def replace_t_with_space(documents):
return [doc.page_content.replace("\n", " ").replace("\t", " ") for doc in documents]
def encode_pdfs_to_qdrant(uploaded_files, collection_name, chunk_size=3000, chunk_overlap=200):
text_splitter = RecursiveCharacterTextSplitter(chunk_size=chunk_size, chunk_overlap=chunk_overlap)
embeddings = HuggingFaceEmbeddings(model_name="sentence-transformers/all-MiniLM-L6-v2")
all_points = []
doc_id = 0
for uploaded_file in uploaded_files:
with open(uploaded_file.name, "wb") as f:
f.write(uploaded_file.read())
loader = PyPDFLoader(uploaded_file.name)
documents = loader.load()
texts = text_splitter.split_documents(documents)
cleaned_texts = replace_t_with_space(texts)
document_objects = [Document(page_content=text) for text in cleaned_texts]
vectors = embeddings.embed_documents([doc.page_content for doc in document_objects])
for i, vector in enumerate(vectors):
all_points.append(PointStruct(
id=doc_id,
vector=vector,
payload={"text": document_objects[i].page_content, "filename": uploaded_file.name}
))
doc_id += 1
#os.remove(uploaded_file.name) # Clean up after processing
if not qdrant_client.collection_exists(collection_name):
qdrant_client.create_collection(
collection_name=collection_name,
vectors_config=VectorParams(size=len(vectors[0]), distance="Cosine")
)
qdrant_client.upsert(collection_name=collection_name, points=all_points)
def query_qdrant(collection_name, query, n_retrieved=10):
embeddings = HuggingFaceEmbeddings(model_name="sentence-transformers/all-MiniLM-L6-v2")
query_vector = embeddings.embed_query(query)
results = qdrant_client.search(collection_name, query_vector=query_vector, limit=n_retrieved)
retrieved_texts = [result.payload["text"] for result in results]
scores = [result.score for result in results]
return retrieved_texts, scores
import requests
def search_web(query):
API_URL = "https://api.tavily.com/search"
API_KEY = "tvly-dev-...............AHwdV" # Replace with your actual API key
payload = {
"query": query,
"topic": "general",
"search_depth": "basic",
"max_results": 3, # Adjust based on need
"time_range": None,
"days": 3,
"include_answer": True,
"include_raw_content": False,
"include_images": False,
"include_image_descriptions": False,
"include_domains": [],
"exclude_domains": []
}
headers = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
}
try:
response = requests.post(API_URL, json=payload, headers=headers, timeout=10)
response.raise_for_status() # Raises an error for HTTP issues
results = response.json().get("results", [])
if results:
return "\n\n".join(result.get("answer", result.get("snippet", "No snippet available")) for result in results)
else:
return "No results found."
except requests.exceptions.RequestException as e:
return f"Error fetching results from Tavily: {e}"
# SimpleRAG Class
class SimpleRAG:
def __init__(self, llm, collection_name, similarity_threshold, n_retrieved=10):
self.llm = llm
self.collection_name = collection_name
self.similarity_threshold = similarity_threshold
self.n_retrieved = n_retrieved
def retrieve_documents(self, query):
return query_qdrant(self.collection_name, query, self.n_retrieved)
def generate_answer(self, query):
documents, scores = self.retrieve_documents(query)
max_score = max(scores) if scores else 0
if max_score < self.similarity_threshold:
return {
"answer": "No relevant content found locally. Would you like to search the web?",
"status": "needs_web_search",
"documents": documents,
"scores": scores
}
context = "\n\n".join(documents)
prompt_template = """Answer the following question based on the context. If unsure, say 'I don't know.'
Context:
{context}
Question: {question}
Answer:"""
prompt = ChatPromptTemplate.from_template(prompt_template)
chain = RunnableSequence(RunnablePassthrough(), prompt, self.llm, StrOutputParser())
answer = chain.invoke({"context": context, "question": query})
return {"answer": answer, "status": "local_answer", "documents": documents, "scores": scores}
# Streamlit Interface
st.title("RAG PDF Parsing with Tavily Web Search Fallback")
st.write("Locally hosted LLM with vector search and web search capabilities")
# User Input for Similarity Threshold
similarity_threshold = st.slider(
"Set Top Similarity Score",
min_value=0.0,
max_value=1.0,
value=0.2,
step=0.01
)
# PDF Upload Section
uploaded_files = st.file_uploader("Upload PDFs", type=["pdf"], accept_multiple_files=True)
collection_name = st.text_input("Collection Name", value="my_collection")
if uploaded_files and st.button("Upload to VectorDB"):
with st.spinner("Uploading documents..."):
encode_pdfs_to_qdrant(uploaded_files, collection_name)
st.success("PDFs uploaded and stored in Qdrant Vector DB!")
# Query Section (Visible after Upload)
if qdrant_client.collection_exists(collection_name):
query = st.text_area("Enter your question", height=150)
if st.button("Search"):
with st.spinner("Processing query..."):
rag = SimpleRAG(llm=llm, collection_name=collection_name, similarity_threshold=similarity_threshold)
result = rag.generate_answer(query)
st.session_state.current_result = result
# Display results and agentic workflow
if 'current_result' in st.session_state:
result = st.session_state.current_result
st.subheader("Local Search Results")
st.write(f"Top similarity score: {max(result['scores']) if result['scores'] else 0:.2f}")
if result['status'] == 'needs_web_search':
st.warning(result['answer'])
if st.button("Proceed to Web Search"):
with st.spinner("Searching web..."):
web_results = search_web(query)
prompt_template = """Answer based on web results:
{context}
Question: {question}
Answer:"""
prompt = ChatPromptTemplate.from_template(prompt_template)
chain = RunnableSequence(RunnablePassthrough(), prompt, llm, StrOutputParser())
web_answer = chain.invoke({"context": web_results, "question": query})
st.session_state.web_answer = web_answer
elif result['status'] == 'local_answer':
st.success("Local Answer:")
st.write(result['answer'])
# Display web search results if available
if 'web_answer' in st.session_state:
st.subheader("Web Search Results")
st.write(st.session_state.web_answer)
Running the Application
streamlit run RAG_PDF_Parsing_with_Tavily_web_search.pyAccess the interface at:
- Local URL: http://localhost:8501
- Network URL: http://[your-ip]:8501
Required services must be running:
- Qdrant server on port 6333
- Ollama server on port 11434
Conclusion
This system exemplifies a cutting-edge Retrieval-Augmented Generation (RAG) framework, seamlessly integrating local inference and hybrid search capabilities to enhance document intelligence and knowledge retrieval.
Key Features and Innovations:
- Efficient Local LLM Inference: Utilizes Ollama to run Llama 3.2 or DeepSeek-R1 models locally, ensuring fast, cost-effective, and private AI-driven responses.
- Hybrid Search Architecture: Combines local vector search (Qdrant) with web-based knowledge retrieval (Tavily API), ensuring comprehensive and accurate information sourcing.
- Advanced PDF Document Processing: Implements an automated document ingestion pipeline, leveraging LangChain’s text-splitting and embedding strategies to efficiently index and retrieve relevant content.
Scalability and Future Enhancements:
The architecture is designed with scalability and modularity in mind, making it adaptable for multi-modal document processing (text, images, and structured data) and enterprise-scale deployments. Future iterations may incorporate:
- Multi-document and multi-modal retrieval (e.g., handling images, tables, and scanned PDFs with OCR).
- Fine-tuned domain-specific embeddings for improved contextual understanding.
- Enterprise integrations with knowledge management systems, compliance platforms, and data lakes.
By combining local AI processing with dynamic web search, this system offers a highly efficient, cost-effective, and intelligent knowledge retrieval solution for diverse applications in research, enterprise AI, and automated document understanding.
Sequence Flow of PDF Parsing with Tavily Web Search Fallback
Class Diagram of PDF Parsing with Tavily Web Search Fallback
Candidate Resume - 1
Candidate Resume - 2
Candidate Resume - 3
Streamlit UI - 1
Streamlit UI - 2
Streamlit UI - 3
Streamlit UI - 4
Qdrant UI
Reference Links
- Streamlit: Streamlit Official Site
- Ollama Installation on Local Host: Ollama GitHub Repository
- Running Llama 3.2 on Local Host using Ollama: Ollama Llama3 Library
- LangChain Tools Documentation: LangChain Tools Guide
- Tavily Search API: Tavily API Documentation
- Qdrant Vector Database: Qdrant Documentation
- Sentence Transformers: Sentence-Transformers Library